本文部分内容来自《Redis开发与运维》一书,转载请声明。
一、现象和危害
线上有台机器内存接近了90%,总内存为24G,整个部署如下图:
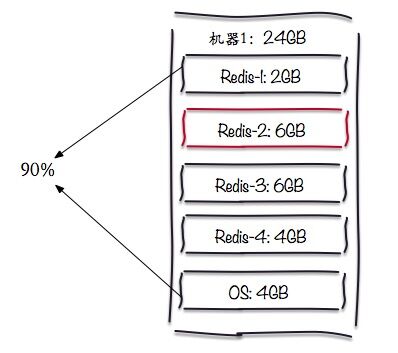
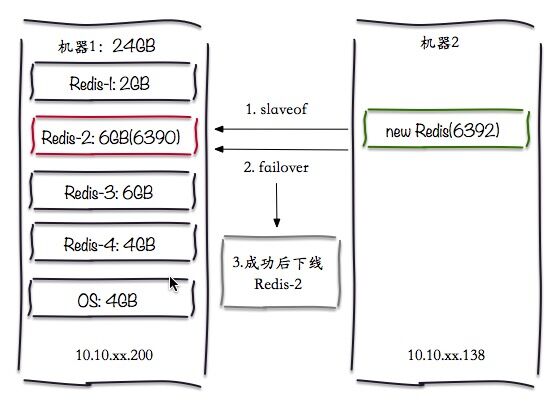
现要将Redis-2迁移走,由于特殊原因此节点没有slave节点,需要添加一个slave节点,然后做failover操作。
通过对日志的观察,发现主从不停地做全量复制。
1.slave首次连接master做全量复制。
2.slave与master连接断开
3.slave与master重连,重新开始全量复制。(因为复制偏移量不够,无法达到部分复制)
危害: 很明显这样会进入无限次全量复制的模式,本身分片比较大,对机器资源有一定开销,会对该机器上其他实例造成影响。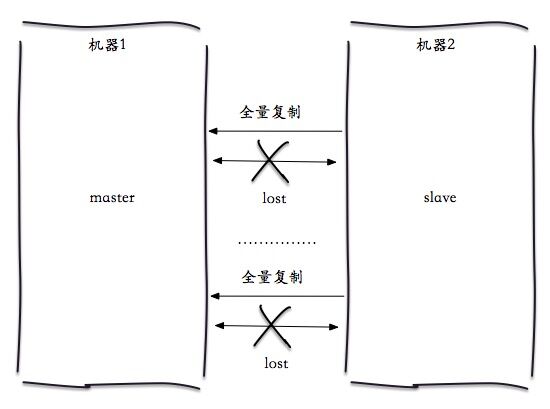
二、分析
1.网络原因导致重连:
(1) 添加的slave为同一个网段,使用redis-cli latency未测试出异常
(2) 添加另一个slave节点,发现依然出现上述情况。
2.Redis版本造成。
在日志中发现了如下一句话:
初步怀疑是Redis版本造成,master:3.0.2,slave:3.0.5,于是模拟实验一下,发现主从复制正常,而且从(not critical)可以看到应该问题不在这里。
3.连接确实由于某些原因断开。
到现在还有看主节点的日志,如下:
(1) master节点接收到了slave节点的复制请求,并生成RDB传给slave节点。
(2) slave节点的客户端连接被杀掉,由于超过了client-output-buffer-limit slave,cachecloud的使用的是512mb 128mb 60。由于分片比较大全量复制时间较长,且master写入量较大,所以slave节点的客户端被干掉了(omem=266324615)。
实际上已经收到报警了:提示client_longest_output_list过大。
综上分析可以确定原因了。
三、后期优化
1.对于写入量大,且分片较大的情况,可以适当增大client-output-buffer-limit slave
2.减少大分片的使用,尽量每个节点控制在4GB以内。
3.可以对一些关键日志进行监控,帮助快速定位问题。